is_hashed = (block->index != NULL); if (is_hashed) { /* TO DO: Can we skip this if none of the fields index->search_info->curr_n_fields are being updated? */
/* The function row_upd_changes_ord_field_binary works only if the update vector was built for a clustered index, we must NOT call it if index is secondary */ if (!dict_index_is_clust(index) || row_upd_changes_ord_field_binary(index, update, thr, NULL, NULL)) { /* Remove possible hash index pointer to this record */ btr_search_update_hash_on_delete(cursor); } rw_lock_x_lock(btr_get_search_latch(index)); }
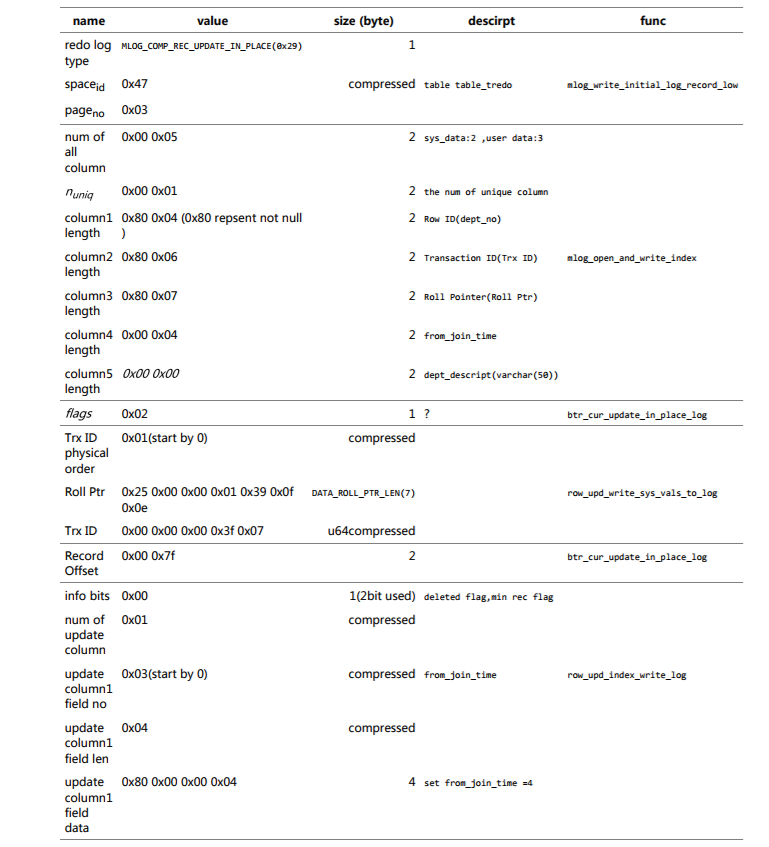
/***********************************************************//**Writes a redo log record of updating a record in-place. */ void btr_cur_update_in_place_log( /*========================*/ ulint flags, /*!< in: flags */ const rec_t* rec, /*!< in: record */ dict_index_t* index, /*!< in: index of the record */ const upd_t* update, /*!< in: update vector */ trx_id_t trx_id, /*!< in: transaction id */ roll_ptr_t roll_ptr, /*!< in: roll ptr */ mtr_t* mtr) /*!< in: mtr */ { byte* log_ptr; const page_t* page = page_align(rec); ut_ad(flags < 256); ut_ad(!!page_is_comp(page) == dict_table_is_comp(index->table)); log_ptr = mlog_open_and_write_index(mtr, rec, index, page_is_comp(page) ? MLOG_COMP_REC_UPDATE_IN_PLACE : MLOG_REC_UPDATE_IN_PLACE, 1 + DATA_ROLL_PTR_LEN + 14 + 2 + MLOG_BUF_MARGIN); if (!log_ptr) { /* Logging in mtr is switched off during crash recovery */ return; } /* For secondary indexes, we could skip writing the dummy system fields to the redo log but we have to change redo log parsing ofMLOG_REC_UPDATE_IN_PLACE/MLOG_COMP_REC_UPDATE_IN_PLACE or we have to addnew redo log record. For now, just write dummy sys fields to the redolog if we are updating a secondary index record.*/ mach_write_to_1(log_ptr, flags); log_ptr++; if (dict_index_is_clust(index)) { log_ptr = row_upd_write_sys_vals_to_log( index, trx_id, roll_ptr, log_ptr, mtr); } else { /* Dummy system fields for a secondary index */ /* TRX_ID Position */ log_ptr += mach_write_compressed(log_ptr, 0); /* ROLL_PTR */ trx_write_roll_ptr(log_ptr, 0); log_ptr += DATA_ROLL_PTR_LEN; /* TRX_ID */ log_ptr += mach_u64_write_compressed(log_ptr, 0); } mach_write_to_2(log_ptr, page_offset(rec)); log_ptr += 2; row_upd_index_write_log(update, log_ptr, mtr); }
/********************************************************//**Opens a buffer for mlog, writes the initial log record and,if needed, the field lengths of an index.@return buffer, NULL if log mode MTR_LOG_NONE */
byte* mlog_open_and_write_index( /*======================*/ mtr_t* mtr, /*!< in: mtr */ const byte* rec, /*!< in: index record or page */ constdict_index_t* index, /*!< in: record descriptor */ mlog_id_t type, /*!< in: log item type */ ulint size) /*!< in: requested buffer size in bytes (if 0, calls mlog_close() and returns NULL) */ { byte* log_ptr; const byte* log_start; const byte* log_end; ut_ad(!!page_rec_is_comp(rec) == dict_table_is_comp(index->table)); if (!page_rec_is_comp(rec)) { log_start = log_ptr = mlog_open(mtr, 11 + size); if (!log_ptr) { return(NULL); /* logging is disabled */ } log_ptr = mlog_write_initial_log_record_fast(rec, type, log_ptr, mtr); log_end = log_ptr + 11 + size; } else { ulint i; ulint n = dict_index_get_n_fields(index); ulint total = 11 + size + (n + 2) * 2; ulint alloc = total; if (alloc > mtr_buf_t::MAX_DATA_SIZE) { alloc = mtr_buf_t::MAX_DATA_SIZE; } /* For spatial index, on non-leaf page, we just keep2 fields, MBR and page no. */ if (dict_index_is_spatial(index) && !page_is_leaf(page_align(rec))) { n = DICT_INDEX_SPATIAL_NODEPTR_SIZE; } log_start = log_ptr = mlog_open(mtr, alloc); if (!log_ptr) { return(NULL); /* logging is disabled */ } log_end = log_ptr + alloc; log_ptr = mlog_write_initial_log_record_fast( rec, type, log_ptr, mtr); mach_write_to_2(log_ptr, n); log_ptr += 2; if (page_is_leaf(page_align(rec))) { mach_write_to_2( log_ptr, dict_index_get_n_unique_in_tree(index)); } else { mach_write_to_2( log_ptr, dict_index_get_n_unique_in_tree_nonleaf(index)); } log_ptr += 2; for (i = 0; i < n; i++) { dict_field_t* field; constdict_col_t* col; ulint len; field = dict_index_get_nth_field(index, i); col = dict_field_get_col(field); len = field->fixed_len; ut_ad(len < 0x7fff); if (len == 0 && (DATA_BIG_COL(col))) { /* variable-length fieldwith maximum length > 255 */ len = 0x7fff; } if (col->prtype & DATA_NOT_NULL) { len |= 0x8000; } if (log_ptr + 2 > log_end) { mlog_close(mtr, log_ptr); ut_a(total > (ulint) (log_ptr - log_start)); total -= log_ptr - log_start; alloc = total; if (alloc > mtr_buf_t::MAX_DATA_SIZE) { alloc = mtr_buf_t::MAX_DATA_SIZE; } log_start = log_ptr = mlog_open(mtr, alloc); if (!log_ptr) { return(NULL); /* logging is disabled */ } log_end = log_ptr + alloc; } mach_write_to_2(log_ptr, len); log_ptr += 2; } } if (size == 0) { mlog_close(mtr, log_ptr); log_ptr = NULL; } elseif (log_ptr + size > log_end) { mlog_close(mtr, log_ptr); log_ptr = mlog_open(mtr, size); } return(log_ptr); }
这里对compact记录类型和redundant记录类型做了区分如下:
1 2 3 4 5
if (!page_rec_is_comp(rec)) { // redundant record type redo log index } else { // compact record type redo log index }
由于我们的类型是compact因此我们只关注下面的分支。 从mtr中的log buffer获取redo buffer 将重点放在comapct record type上面,刚开始可以看到从mtr的log buffer中获取缓冲块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
ulint i; ulint n = dict_index_get_n_fields(index); ulint total = 11 + size + (n + 2) * 2; ulint alloc = total; if (alloc > mtr_buf_t::MAX_DATA_SIZE) { alloc = mtr_buf_t::MAX_DATA_SIZE; } /* For spatial index, on non-leaf page, we just keep2 fields, MBR and page no. */ if (dict_index_is_spatial(index) && !page_is_leaf(page_align(rec))) { n = DICT_INDEX_SPATIAL_NODEPTR_SIZE; } log_start = log_ptr = mlog_open(mtr, alloc); if (!log_ptr) { return(NULL); /* logging is disabled */ } log_end = log_ptr + alloc;
/********************************************************//**Writes the initial part of a log record (3..11 bytes).If the implementation of this function is changed, allsize parameters to mlog_open() should be adjusted accordingly!@return new value of log_ptr */ UNIV_INLINE byte* mlog_write_initial_log_record_fast( /*===============================*/ const byte* ptr, /*!< in: pointer to (inside) a buffer frame holding the file page where modification is made */ mlog_id_t type, /*!< in: log item type: MLOG_1BYTE, ... */ byte* log_ptr,/*!< in: pointer to mtr log which has been opened */ mtr_t* mtr) /*!< in/out: mtr */ { const byte* page; ulint space; ulint offset; ut_ad(log_ptr); ut_d(mtr->memo_modify_page(ptr)); page = (const byte*) ut_align_down(ptr, UNIV_PAGE_SIZE); space = mach_read_from_4(page + FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID); offset = mach_read_from_4(page + FIL_PAGE_OFFSET); /* check whether the page is in the doublewrite buffer;the doublewrite buffer is located in pagesFSP_EXTENT_SIZE, ..., 3 * FSP_EXTENT_SIZE - 1 in thesystem tablespace */ if (space == TRX_SYS_SPACE && offset >= FSP_EXTENT_SIZE && offset < 3 * FSP_EXTENT_SIZE) { if (buf_dblwr_being_created) { /* Do nothing: we only come to this branch in an InnoDB database creation. We do not redo log anything for the doublewrite buffer pages. */
return(log_ptr); } else { ib::error() << "Trying to redo log a record of type " << type << " on page " << page_id_t(space, offset) << "in the" " doublewrite buffer, continuing anyway." " Please post a bug report to" " bugs.mysql.com."; ut_ad(0); } } return(mlog_write_initial_log_record_low(type, space, offset, log_ptr, mtr));
这里我有一个疑问即:
1
/*Do nothing: we only come to this branch in an InnoDB database creation. We do not redo loganything for the doublewrite buffer pages. */
/** Writes a log record about an operation.param[in] type redo log record type*/
//@param[in] space_id tablespace identifier //@param[in] page_no page number //@param[in,out] log_ptr current end of mini-transaction log //@param[in,out] mtr mini-transaction //@return end of mini-transaction log
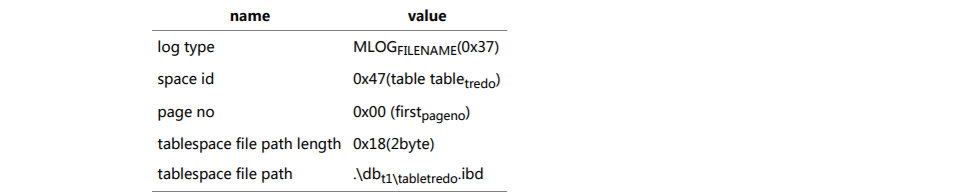
ut_ad( /** note the first use of a tablespace file since checkpoint */ type == MLOG_FILE_NAME /** delete a tablespace file that starts with (space_id,page_no) */ || type == MLOG_FILE_DELETE /** log record about creating an .ibd file, with format */ || type == MLOG_FILE_CREATE2 /** rename a tablespace file that starts with (space_id,page_no) */ || type == MLOG_FILE_RENAME2 /** notify that an index tree is being loaded without writing redo log about individual pages */ || type == MLOG_INDEX_LOAD /** Table is being truncated. (Marked only for file-per-table) */ || type == MLOG_TRUNCATE /*Check if a tablespace is associated with the mini-transaction(needed for generating a MLOG_FILE_NAME record)*/ || mtr->is_named_space(space_id));
/*********************************************************//**Writes a ulint in a compressed form where the first byte codes thelength of the stored ulint. We look at the most significant bits ofthe byte. If the most significant bit is zero, it means 1-byte storage,else if the 2nd bit is 0, it means 2-byte storage, else if 3rd is 0,it means 3-byte storage, else if 4th is 0, it means 4-byte storage,else the storage is 5-byte.@return compressed size in bytes */ UNIV_INLINE ulint mach_write_compressed( /*==================*/ byte* b, /*!< in: pointer to memory where to store */ ulint n) /*!< in: ulint integer (< 2^32) to be stored */ { ut_ad(b); if (n < 0x80) { /* 0nnnnnnn(7 bits) */ mach_write_to_1(b, n); return(1); } elseif (n < 0x4000) { /* 10nnnnnn nnnnnnnn (14 bits) */ mach_write_to_2(b, n | 0x8000); return(2); } elseif (n < 0x200000) { /* 110nnnnn nnnnnnnn nnnnnnnn (21 bits) */ mach_write_to_3(b, n | 0xC00000); return(3); } elseif (n < 0x10000000) { /* 1110nnnn nnnnnnnn nnnnnnnn nnnnnnnn (28 bits) */ mach_write_to_4(b, n | 0xE0000000); return(4); } else { /* 11110000 nnnnnnnn nnnnnnnn nnnnnnnn nnnnnnnn (32 bits) */ mach_write_to_1(b, 0xF0); mach_write_to_4(b + 1, n); return(5); } }
写入 srcC++{index->nuniq/!< number of fields from the beginning which are enough to determine an index entry uniquely /} 但是不知道: 这个域的作用是什么? 以及为什么要写入? 回去查资料发现这个srcC++{nuniq}代表的是记录中唯一性列的个数
/* For secondary indexes, we could skip writing the dummy system fields to the redo log but we have to change redo log parsing ofMLOG_REC_UPDATE_IN_PLACE/MLOG_COMP_REC_UPDATE_IN_PLACE or we have to addnew redo log record. For now, just write dummy sys fields to the redo log if we are updating a secondary index record.*/ mach_write_to_1(log_ptr, flags); log_ptr++;
/*********************************************************************//**Writes into the redo log the values of trx id and roll ptr and enough infoto determine their positions within a clustered index record.@return new pointer to mlog */
byte* row_upd_write_sys_vals_to_log( /*==========================*/ dict_index_t* index, /*!< in: clustered index */ trx_id_t trx_id, /*!< in: transaction id */ roll_ptr_t roll_ptr,/*!< in: roll ptr of the undo log record */ byte* log_ptr,/*!< pointer to a buffer of size > 20 openedin mlog */ mtr_t* mtr MY_ATTRIBUTE((unused))) /*!< in: mtr */ { ut_ad(dict_index_is_clust(index)); ut_ad(mtr); log_ptr += mach_write_compressed(log_ptr, dict_index_get_sys_col_pos( index, DATA_TRX_ID)); trx_write_roll_ptr(log_ptr, roll_ptr); log_ptr += DATA_ROLL_PTR_LEN; log_ptr += mach_u64_write_compressed(log_ptr, trx_id); return(log_ptr); }
upd_field = upd_get_nth_field(update, i); new_val = &(upd_field->new_val); len = dfield_get_len(new_val); /* If this is a virtual column, mark it using specialfield_no */ ulint field_no = upd_fld_is_virtual_col(upd_field) ? REC_MAX_N_FIELDS + upd_field->field_no : upd_field->field_no; log_ptr += mach_write_compressed(log_ptr, field_no); log_ptr += mach_write_compressed(log_ptr, len);
/** Write the redo log record, add dirty pages to the flush list and releasethe resources. */ void mtr_t::Command::execute() { ut_ad(m_impl->m_log_mode != MTR_LOG_NONE); if (const ulint len = prepare_write()) { finish_write(len); } if (m_impl->m_made_dirty) { log_flush_order_mutex_enter(); } /* It is now safe to release the log mutex because theflush_order mutex will ensure that we are the first oneto insert into the flush list. */ log_mutex_exit(); m_impl->m_mtr->m_commit_lsn = m_end_lsn; release_blocks(); if (m_impl->m_made_dirty) { log_flush_order_mutex_exit(); } release_latches(); release_resources(); }
提交准备: mtr_t::Command::prepare_write()
1. 代码1 :定义了各种不同的日志模式下日志的写法
1 2 3 4 5 6 7 8 9 10 11 12
switch (m_impl->m_log_mode) { case MTR_LOG_SHORT_INSERTS: ut_ad(0); /* fall through (write no redo log) */ case MTR_LOG_NO_REDO: case MTR_LOG_NONE: ut_ad(m_impl->m_log.size() == 0); log_mutex_enter(); m_end_lsn = m_start_lsn = log_sys->lsn; return(0); case MTR_LOG_ALL: break
if (fil_names_write_if_was_clean(space, m_impl->m_mtr)) { /* This mini-transaction was the first one to modifythis tablespace since the latest checkpoint, so some MLOG_FILE_NAME records were appended to m_log. */ ut_ad(m_impl->m_n_log_recs > n_recs); mlog_catenate_ulint( &m_impl->m_log, MLOG_MULTI_REC_END, MLOG_1BYTE); len = m_impl->m_log.size(); }
/* This mini-transaction was the first one to modifythis tablespace since the latest checkpoint, sosome MLOG_FILE_NAME records were appended to m_log. */
/* This mini-transaction was the first one to modifythis tablespace since the latest checkpoint, sosome MLOG_FILE_NAME records were appended to m_log. */ ut_ad(m_impl->m_n_log_recs > n_recs); mlog_catenate_ulint( &m_impl->m_log, MLOG_MULTI_REC_END, MLOG_1BYTE); len = m_impl->m_log.size();
else { /* This was not the first time of dirtying atablespace since the latest checkpoint. */ ut_ad(n_recs == m_impl->m_n_log_recs); if (n_recs <= 1) { ut_ad(n_recs == 1); /* Flag the single log record as theonly record in this mini-transaction. */ *m_impl->m_log.front()->begin() |= MLOG_SINGLE_REC_FLAG; } else {/* Because this mini-transaction comprisesmultiple log records, append MLOG_MULTI_REC_END at the end. */ mlog_catenate_ulint( &m_impl->m_log, MLOG_MULTI_REC_END, MLOG_1BYTE); len++; } }
/* return with warning output to avoid deadlock */ if (!log_has_printed_chkp_margine_warning || difftime(time(NULL), log_last_margine_warning_time) > 15) { log_has_printed_chkp_margine_warning = true; log_last_margine_warning_time = time(NULL); ib::error() << "The transaction log files are too" " small for the single transaction log (size=" << len << "). So, the last checkpoint age" " might exceed the log group capacity " << log_sys->log_group_capacity << "."; } return; }
/* Our margin check should ensure that we never reach this condition.Try to do checkpoint once. We cannot keep waiting here as it mightresult in hang in case the current mtr has latch on oldest lsn */ if (log_sys->lsn - log_sys->last_checkpoint_lsn + margin > log_sys->log_group_capacity) { /* The log write of 'len' might overwrite the transaction logafter the last checkpoint. Makes checkpoint. */ bool flushed_enough = false; if (log_sys->lsn - log_buf_pool_get_oldest_modification() + margin <= log_sys->log_group_capacity) { flushed_enough = true; } log_sys->check_flush_or_checkpoint = true; log_mutex_exit(); DEBUG_SYNC_C("margin_checkpoint_age_rescue"); if (!flushed_enough) { os_thread_sleep(100000); } log_checkpoint(true, false); log_mutex_enter(); }
#ifndef UNIV_HOTBACKUP /** Append a string to the log.*/ // @param[in] str string //@param[in] len string length // @param[out] start_lsn start LSN of the log record // @return end lsn of the log record, zero if did not succeed
UNIV_INLINE lsn_t log_reserve_and_write_fast( constvoid* str, ulint len, lsn_t* start_lsn) { const ulint data_len = len + log_sys->buf_free % OS_FILE_LOG_BLOCK_SIZE; if (data_len >= OS_FILE_LOG_BLOCK_SIZE - LOG_BLOCK_TRL_SIZE) { /* The string does not fit within the current log block or the log block would become full */ return(0); } *start_lsn = log_sys->lsn; memcpy(log_sys->buf + log_sys->buf_free, str, len); //更新log_sys buffer block 的 LOG_BLOCK_HDR_DATA_LEN log_block_set_data_len( reinterpret_cast<byte*>(ut_align_down( log_sys->buf + log_sys->buf_free, OS_FILE_LOG_BLOCK_SIZE)), data_len); log_sys->buf_free += len; log_sys->lsn += len; return(log_sys->lsn) } /************************************************************//**Sets the log block data length. */ UNIV_INLINE void log_block_set_data_len( /*===================*/ byte* log_block, /*!< in/out: log block */ ulint len) /*!< in: data length */ { mach_write_to_2(log_block + LOG_BLOCK_HDR_DATA_LEN, len); }
// func: log_margin_checkpoint_age /* Our margin check should ensure that we never reach this condition.Try to do checkpoint once. We cannot keep waiting here as it might result in hang in case the current mtr has latch on oldest lsn */ if (log_sys->lsn - log_sys->last_checkpoint_lsn + margin > log_sys->log_group_capacity) { /*code*/ log_sys->check_flush_or_checkpoint = true; log_checkpoint(true, false); }
结论1:如果当前的drity page所产生的redo log大于整个 redo log group 的容量则会将 redolog_sys buffer 里面的日志刷盘checkpoint
情形2:当事务提交时,会将 redo logsysbuffer 刷盘
代码(func: trx_flush_log_if_needed_low)
1 2 3 4 5 6 7 8 9 10 11 12 13
switch (srv_flush_log_at_trx_commit) { case 2: /* Write the log but do not flush it to disk */ flush = false; /* fall through */ case 1: /* Write the log and optionally flush it to disk */ log_write_up_to(lsn, flush); return; case 0: //每隔1s将redo写盘 /* Do nothing */ return; }
/********************************************************************//**The master thread is tasked to ensure that flush of log file happens once every second in the background. This is to ensure that not more than one second of trxs are lost in case of crash when innodb_flush_logs_at_trx_commit != 1 */ static void srv_sync_log_buffer_in_background(void) /*===================================*/ { time_t current_time = time(NULL); srv_main_thread_op_info = "flushing log"; //这里srv_flush_log_at_timeout if (difftime(current_time, srv_last_log_flush_time) >= srv_flush_log_at_timeout) { log_buffer_sync_in_background(true); srv_last_log_flush_time = current_time; srv_log_writes_and_flush++; } }
/* Make a new checkpoint */ // if (cur_time % SRV_MASTER_CHECKPOINT_INTERVAL == 0) { srv_main_thread_op_info = "making checkpoint"; log_checkpoint(TRUE, FALSE); MONITOR_INC_TIME_IN_MICRO_SECS( MONITOR_SRV_CHECKPOINT_MICROSECOND, counter_time); }
其频率是7s刷一次盘。
srv_master_do_idle_tasks 中的代码:
1 2 3 4 5
/* Make a new checkpoint */ srv_main_thread_op_info = "making checkpoint"; log_checkpoint(TRUE, FALSE); MONITOR_INC_TIME_IN_MICRO_SECS(MONITOR_SRV_CHECKPOINT_MICROSECOND, counter_time);